
点评项目
点评项目是前后端分离项目,前端部署在nginx服务器上,后端部署在tomcat上。
用户登录
-
权限认证方式
-
HTTP是无状态的; -
Session(会话)认证:服务器为了保存用户状态而创建的一个对象。key-value形式存储; -
Token(令牌):由服务端生成的一串字符串,作为客户端进行请求的一个凭证;当用户第一次登陆后,服务器会生成一个Token并返回给客户端,之后客户端再进行需要权限的请求时只需要带上这个Token即可,无需再携带用户名和密码进行认证;通过某种算法策略生成唯一的Token;
-
-
集群**
session共享问题**:集群模式下多台tomcat服务器不共享session存储空间,当请求切换到不同tomcat服务时导致数据丢失的问题。因为
Redis满足数据共享,内存存储,k-v键值对结构,因此使用Redis替代session可以解决session集群共享问题; -
登陆验证流程
- 前端提交手机号和验证码;
- 校验手机号,如果不符合,返回错误信息;
- 从
redis获取验证码并校验,如果不一致,则返回错误信息; - 如果一致,根据手机号查询用户;
- 判断用户是否存在,若不存在,创建新用户并保存(注册);
- 保存用户信息到
redis中;- 生成随机
token,作为登录令牌; - 将User对象转为
HashMap存储; - 存入
Redis,并设置key有效期; - 返回
token;
- 生成随机
-
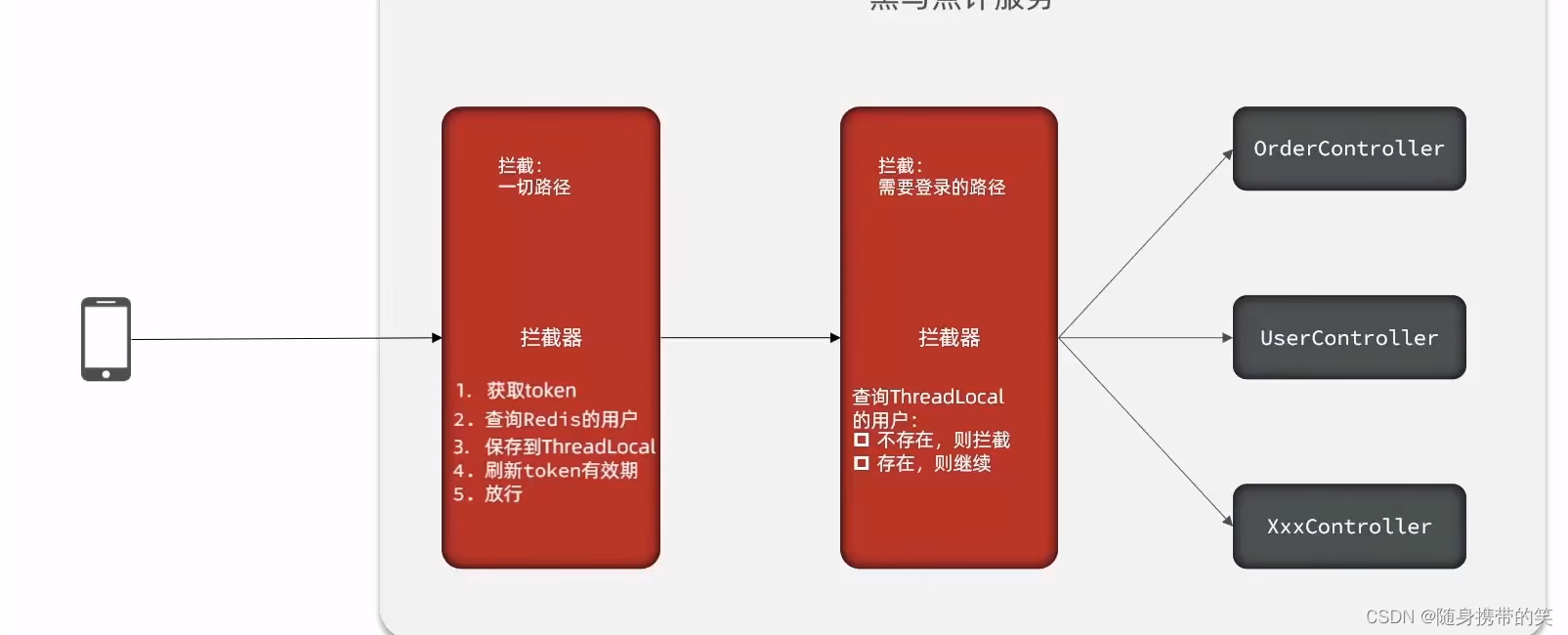
刷新
Token有效期拦截器:因为Token设置的有效期是固定的,因此如果用户一直在登陆状态,则需要一直刷新Token的有效期;- 拦截所有请求
- 获取
Token; - 基于
Token获取Redis中的用户信息; - 保存用户信息到
ThreadLocal; - 刷新
Token有效期;
-
登录拦截器:拦截需要用户登录的请求,查询
ThreadLocal中是否存在用户,存在则放行;
商户查询缓存
简介
缓存是数据交换得缓冲区(Cache),用于存储临时数据,一般读写性能较高;
-
缓存的作用
- 降低后端负载
- 提高读写速率,降低响应速率
-
缓存的成本
- 数据一致性成本
- 代码维护成本
- 运维成本(集群部署等)
-
通常我们这样使用缓存:
- 写请求只写数据库
- 读请求先读缓存,如果缓存不存在,则从数据库读取,并更新缓存
- 同时,写入缓存中的数据,都设置失效时间

这样一来,缓存中不经常访问的数据,随着时间的推移,都会逐渐「过期」淘汰掉,最终缓存中保留的,都是经常被访问的「热数据」,缓存利用率得以最大化。
缓存更新策略
-
缓存更新策略
- 内存淘汰:利用Redis的内存淘汰机制;
- 超时剔除:给缓存数据添加超时时间;
- 主动更新:编写业务逻辑,在修改数据库的同时,更新缓存;
-
删除缓存还是更新缓存?
- 更新缓存:每次更新数据库都需要更新缓存,无效写操作较多;
- 删除缓存:更新数据库时让缓存失效,查询时再更新缓存(更优)
-
如何保证缓存和数据库操作的原子性?
- 单体系统,将缓存和数据库放在一个事务中;
- 分布式系统:利用TCC等分布式事务方案;
-
这里存在数据一致性问题,当数据发生更新时,我们不仅要更新数据库,还要一并更新缓存。这两个操作并非是原子的,所以有先后顺序;
-
先删除缓存,再更新数据库:
-
初始化(数据库:1 ,缓存:1)
-
线程1 删除缓存后(数据库:1 ,缓存:null)
-
线程2 前来查询缓存未命中,查询数据库,并将查询到的数据写入缓存(数据库:1 ,缓存:1)
-
线程1 再更新数据库(数据库:2 ,缓存:1)
-
导致数据库和缓存数据不一致问题;这种情况发生的概率较大,因为Redis的读写速度比数据库快很多,并发情况下很容易发生这种情况。
-
-
先更新数据库,再删除缓存
- 初始化,恰好缓存失效(数据库:1 ,缓存:null)
- 线程1 查询缓存未命中并查询数据库(1)
- 线程2 更新数据库(数据库:2 ,缓存:null)
- 线程2 删除缓存(数据库:2 ,缓存:null)
- 线程1 写入缓存(数据库:2 ,缓存:1)
- 导致数据库和缓存数据不一致问题;这种情况发生的概率很小(线程1之前缓存恰好失效;Redis写入速度很快,在其之前有线程插入并更新数据库的概率很小)
-
-
因此,缓存更新策略的最佳实践方案为:
- 低一致性需求:使用Redis自带的内存淘汰机制;
- 高一致性需求:主动更新,并以超时剔除作为兜底方案;
- 读操作:
- 缓存命中则直接返回;
- 缓存未命中则直接查询数据库,并写入缓存,并设定超时时间;
- 写操作:
- 先写数据库,然后再删除缓存;
- 要确保数据库与缓存操作的原子性;
- 读操作:
缓存穿透
-
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远都不会生效,这些请求都会到数据库。(可能会被无效请求恶意攻击)。
-
解决方案:
-
缓存空对象:对于无效的请求,缓存一个null对象
-
优点:实现简单,维护简单
-
缺点:
- 额外的内存消耗
- 可能造成短期的数据不一致
-
-
布隆过滤
- 请求与Redis缓存之间设置一布隆过滤器,由布隆过滤器判断请求数据是否存在,存在则放行,不存在则直接返回。
- 布隆过滤器并不是存储了所有数据,而是通过某种算法来判断请求数据是否存在。
-
缓存雪崩
- 缓存雪崩是指 同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
- 解决方案:
- 给不同的key添加随机失效时间;
- 利用Redis集群提高服务的可用性;
- 给缓存业务添加降级限流策略;
- 给业务添加多级缓存;
缓存击穿
-
缓存击穿问题也被称为热点key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求在瞬间给数据库带来巨大的冲击。
-
解决方案:
-
互斥锁:查询缓存未命中时,先获取互斥锁,获取锁成功后查询数据库并重建缓存,写入缓存后再释放锁;这样,其他线程请求无法在缓存重建期间查询缓存。
线程需要等待,性能收到影响;可能有死锁风险。
-
逻辑过期:给缓存的数据添加一个逻辑过期字段,而不是真正的给它设置一个TTL。每次查询缓存的时候去判断是否已经超过了我们设置的逻辑过期时间,如果未过期,直接返回缓存数据;如果已经过期则进行缓存重建。
- 优点:
- 线程无需等待,性能较好
- 缺点:
- 不保证一致性(因为会返回过期数据)
- 有额外的内存消耗(同时缓存了逻辑过期时间的字段)
- 实现复杂
- 优点:
-
优惠券秒杀
Redis的计数器,lua脚本Redis,分布式锁,消息队列
分布式全局唯一ID
-
**UUID(通用唯一标识符)**表示一个128位长的唯一值。 它也被普遍称为GUID(全球唯一标识符)。我们可以使用*UUID*类来生成随机文件名,会话或事务ID。 UUID的另一种流行用法是在数据库中生成主键值。有极小的概率会重复。
-
雪花算法
由64位
bit字符组成(Long)
$$
0\quad \quad0000 … 0000\quad\quad\quad 000000 0000 \quad\quad 0000 0000 0000
$$
符号位 时间戳:41 bit 机器ID:10 bit 12 bit 序列号-
组成:
- 符号位:1 bit,生成ID一般均为正数,因此为0;
- 时间戳:41 bit,单位为ms,可以使用约69年;
- 机器ID:10 bit,可以支持1024个分布式机器;
- 序列号:12 bit,表示每ms可以生成$2^{12}=1024$个不同ID;
-
特点
- 按时间递增
- 唯一性
- 生成效率高
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/**
* 生成全局唯一ID(** 雪花算法 **)
*/
public class UIDWorker {
// 开始时间戳
private static final long BEGIN_TIMESTAMP = 1692213900;
private StringRedisTemplate stringRedisTemplate;
public Long nextId(String prefix){
// 生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 机器ID
long machineId = 1;
// 生成序列号(通过Redis自增生成序列)
String nowDateTime = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
long increment = stringRedisTemplate.opsForValue()
.increment("icr" + prefix + ":" + nowDateTime);
// 拼接并返回
long id = timestamp << 22 | machineId << 12 | increment;
return id;
}
} -
-
雪花算法的**时钟回拨 **问题
- 由于雪花算法对于时钟特别敏感,因此如果时钟出现回拨现象,有可能导致获取的ID重复。
- 正常来说只要不是不是有人手贱或者出于泄愤的目的进行干扰,系统的时间漂移是一个在毫秒级别的极短的时间。因此可以在获取 ID 的时候,记录一下当前的时间戳。然后在下一次过来获取的时候,对比一下当前时间戳和上次记录的时间戳,如果发现当前时间戳小于上次记录的时间戳,所以出现了时钟回拨现象,对外抛出异常,本次 ID 获取失败。理论上当前时间戳会很快的追赶上上次记录的时间戳。
超卖问题
-
高并发场景下,做个线程交叉执行可能会出现超卖问题;
-
初始:库存:1; -
线程1:查询库存为1; -
线程2:查询库存为1; -
线程1:扣减库存,下单成功; -
线程2:扣减库存,下单成功; -
库存:-1(出现超买问题);
-
-
解决方案:加锁
-
悲观锁
- 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。
- 例如
Synchronized,Lock都属于悲观锁; - 特点:简单直接,性能差;
-
乐观锁
- 认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时判断是否有其他线程对数据进行了修改。
- 如果没有,则认为是安全的,更新数据;
- 如果游,则重试或者抛出异常;
- 特点:性能好,但容易出现成功率过低的问题;
- 认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时判断是否有其他线程对数据进行了修改。
-
乐观锁的实现方式
-
版本号法:为资源添加一个version版本号,当修改资源后version就加一,修改资源前判断版本号是否被修改;
-
初始:库存:1;( version = 1 ) -
线程1:查询库存为1;( version = 1 ) -
线程2:查询库存为1;( version = 1 ) -
线程1:扣减库存,下单成功;( version = 2 ) -
线程2:此时发现version与查询时的不同,说明资源被其他线程修改,下单失败;
-
-
CAS(
Compare And Swap):CAS算法有三个操作数,通过内存中的值(V)、预期原始值(A)、修改后的新值。
(1)如果内存中的值和预期原始值相等, 就将修改后的新值保存到内存中。
(2)如果内存中的值和预期原始值不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作,直到重试成功。1
2
3
4
5
6// 扣减库存
boolean isSuccess = seckillVoucherService.update()
.setSql("stock = stock - 1") // set stock = stock - 1
.eq("voucher_id", voucherId) // where ...
.eq("stock",voucher.getStock())
.update();该方法能够解决超卖问题,但是高并发场景下成功率过低,影响业务;
-
一人一单
-
业务场景下,同一个用户对同一优惠券只能下一次单。(抵制黄牛!)
-
加
sycronized锁实现1
2
3
4
5
6
7
8
9
10
11
12
13
14
public Result createVoucherOrder(Long voucherId) {
// 获取用户Id
Long userId = UserHolder.getUser().getId();
// toString()底层每次调用都会重新创建一个String对象,导致synchronized失效
// 调用intern()方法:如果字符串池中存在该字符串对象,则直接返回,而不是重新创建一个字符串
synchronized (userId.toString().intern()){
// 一人一单
Long count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if(count>0){
return Result.fail("用户已经抢购过该优惠券!");
}
}
} -
以上代码可能会导致线程安全问题
1
2
3
4
5
6
7
8
9
10
public Result createVoucherOrder(Long voucherId) {
...
synchronized (userId.toString().intern()){
// 一人一单
...
}
// 锁释放,此时其他线程可以进来
// 而事务尚未提交,线程不安全!
} -
优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public Result seckillVoucher(Long voucherId) {
Long userId = UserHolder.getUser().getId();
// toString()底层每次调用都会重新创建一个String对象,导致synchronized失效
// 调用intern()方法:如果字符串池中存在该字符串对象,则直接返回,而不是重新创建一个字符串
synchronized (userId.toString().intern()) {
return this.createVoucherOrder(voucherId); // **事务失效** 问题
// 事务已提交
} // 释放锁
}
public Result createVoucherOrder(Long voucherId) {
...
} -
以上有可能导致事务失效问题,解决方案如下:
1
2
3
4
5
6Long userId = UserHolder.getUser().getId();
synchronized (userId.toString().intern()) {
// 拿到当前对象的代理对象
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
}
分布式锁
简介
-
sycronized只能在一个JVM内部实现不同线程之间的互斥,集群下可能出现线程安全问题 -
分布式锁:满足分布式系统或集群模式下多进程可见的互斥锁。
-
特点:
- 多进程可见
- 互斥
- 高性能
- 高可用
- 安全性
-
实现方式
MySQL Redis 互斥 利用MySQL本身的互斥锁机制 利用setnx命令 高可用 好 好 高性能 一般 好 安全性 断开连接,自动释放锁 利用锁超时时间,到期释放
基于Redis实现分布式锁
-
获取锁
1
2
3
4# 利用setnx的互斥特性
SETNX lock thread1
# 添加锁过期时间,避免服务宕机引起的死锁
EXPIRE lock 30以上两条命令不具备原子性,可以使用以下命令:
1
SET lock thread NX EX 30
-
释放锁
手动释放或超时释放
1
2# 删除即可
DEL lock -
实现Redis分布式锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14public interface ILock {
/**
* 尝试获取锁
* @param timeoutSec 锁持有的超时时间,过期后自动释放
* @return true代表获取锁成功; false代表获取锁失败
*/
boolean tryLock(long timeoutSec);
/**
* 释放锁
*/
void unlock();
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class SimpleRedisLock implements ILock {
private StringRedisTemplate stringRedisTemplate;
private String lockName;
private static final String ID_PREFIX = UUID.randomUUID(true) + "-";
private static final String LOCK_PREFIX = "lock_";
public SimpleRedisLock(StringRedisTemplate stringRedisTemplate, String lockName) {
this.lockName = lockName;
this.stringRedisTemplate = stringRedisTemplate;
}
public boolean tryLock(long timeoutSec) {
/*
获取锁时存入线程标识
解决分布式锁 **误删** 问题
*/
// 获取线程标示
String threadId = ID_PREFIX + Thread.currentThread().getId();
// 获取锁
Boolean isSuccess = stringRedisTemplate.opsForValue()
.setIfAbsent(LOCK_PREFIX + lockName, threadId, timeoutSec, TimeUnit.MINUTES);
// return isSuccess; // 可能会在自动拆箱过程中出现空指针
return Boolean.TRUE.equals(isSuccess);
}
public void unlock() {
/*
释放锁时先获取锁中的线程标识,判断是否与当前标识相同
如果一致则释放锁,不一致则不释放锁;
*/
String threadId = ID_PREFIX + Thread.currentThread().getId();
String id = stringRedisTemplate.opsForValue().get(LOCK_PREFIX + lockName);
if (threadId.equals(id)) {
stringRedisTemplate.delete(LOCK_PREFIX + lockName);
}
}
} -
解决分布式锁 误删 问题
-
线程1:获取锁成功(lock1),执行任务;(任务时间较久或宕机) -
超过超时时间,锁自动释放;
-
线程2:获取锁成功(lock1),执行任务; -
线程1:任务执行成功,释放锁; -
此时
线程2还未执行完毕,线程 1误删了线程 2的锁;
解决方案:
-
-
获取锁时存入线程标识(可以使用
UUID);- 释放锁时先获取锁中的线程标识,判断是否与当前标识相同,如果一致则释放锁,不一致则不释放锁;
-
分布式锁的原子性
-
由于上述判断线程标识与释放锁的操作不具备原子性,因此可能会有线程安全问题;
-
Redis提供了lua脚本功能,在一个脚本中编写多条redis命令,确保多条命令执行时的原子性;
1
EVAL script key [key ...] # 执行脚本
-
-
实现思路总结
- 利用
SETNX命令获取锁,设置过期时间,并存入线程标识; - 释放锁时先判断标识是否一致,一致则删除锁;
- 利用
-
基于
SETNX实现分布式锁的问题:- 不可重入:同一个线程无法多次获取同一把锁;
- 不可重试:获取锁失败时返回false,没有重试机制;
- 超时释放:超时释放虽然可以避免死锁;设置超时时间过短,若业务执行时间过长,也会导致锁释放,存在安全隐患;设置超时时间过长,导致业务停滞;
- 主从一致性
Redisson
-
Redisson使用
-
引入依赖
1
2
3
4
5<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency> -
配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14// Reddision 配置
public class RedissonConfig {
public RedissonClient redissonClient() {
// 配置
Config config = new Config();
// 单节点
config.useSingleServer().setAddress("redis://127.0.0.1:6379").setPassword("lm12138");
// 创建RedissonClient对象
return Redisson.create(config);
}
} -
使用
Redisson1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
private RedissonClient redissonClient;
private void testRedisson() {
// 获取锁,指定锁名称
RLock lock = redissonClient.getLock("anyLock");
boolean isLock = lock.tryLock();
// 判断是否获取锁成功
if(!isLock){
try {
// 业务逻辑
} finally {
// 释放锁
lock.unlock();
}
}
}
-
秒杀优化
-
秒杀流程回顾:
- 查询优惠券(数据库)
- 判断秒杀库存
- 查询订单(数据库)
- 校验一人一单
- 减库存(数据库)
- 创建订单(数据库)
-
异步秒杀:
- 新增秒杀优惠券的同时,将秒杀库存保存到Redis中;
- 基于lua脚本,判断秒杀库存,一人一单,决定用户是否抢购成功
- 如果抢购成功,将优惠券id和用户id存入阻塞队列
- 开启线程任务,不断从阻塞队列中获取信息,实现异步下单功能
点赞与评论
- 基于SortedSet的点赞排行榜
- 从Redis中查询,判断用户是否赞;
- 若未点赞,数据库点赞数 +1,并且将用户和点赞时间(score)存入Redis;
- 若已经点赞,数据库点赞数 -1,并且将用户移除Redis;
- 查询 top5 的点赞用户
zrange key 0 4
好友关注
基于set集合的关注,取关,共同关注和消息推送等功能
附近的商户
redis的GeoHash的应用
UV统计
Redis的HyperLog的统计功能
用户签到
Redis的BitMap数据统计功能








